



A version of this page is available in your language.
Would you like to switch?
A version of this page is available in your language.
Would you like to switch?
Если вы работаете над приложениями, которые напрямую зависят от ончейн-данных, создаете торговый терминал, аналитику, DeFi-примитивы на быстрых сетях, или просто исследуете подходы к обработке и индексации блокчейн-данных, этот пост для вас.
Сегодня мы разберём, как устроены современные решения для индексации блокчейн данных: от базового взаимодействия с нодой до продвинутых инструментов вроде Firehose и Substreams. Поговорим про исторические данные, обработку chain reorg и возможности параллельной обработки, а в конце сравним всё это с Subgraph.
Любая система аналитики, мониторинга или автоматической реакции в блокчейне начинается с одной и той же задачи — извлечения данных из сети.
У нас есть блокчейн, есть ноды, которые обмениваются данными по P2P-протоколу, и есть внешние сервисы, которым нужно понимать, что происходит в сети и как на это реагировать.
Такими сервисами могут быть:
Во всех этих случаях базовая проблема одна:
блокчейн — это источник данных, из которого нужно уметь стабильно, масштабируемо и предсказуемо извлекать информацию.
Чтобы понять, как к этому пришли современные индексеры, имеет смысл начать с самого простого подхода и постепенно проследить эволюцию.
В качестве примера дальше будем использовать Ethereum, как наиболее показательный и распространённый кейс.
Самая простая форма индексации данных в Ethereum строится вокруг ноды и её RPC-интерфейса.
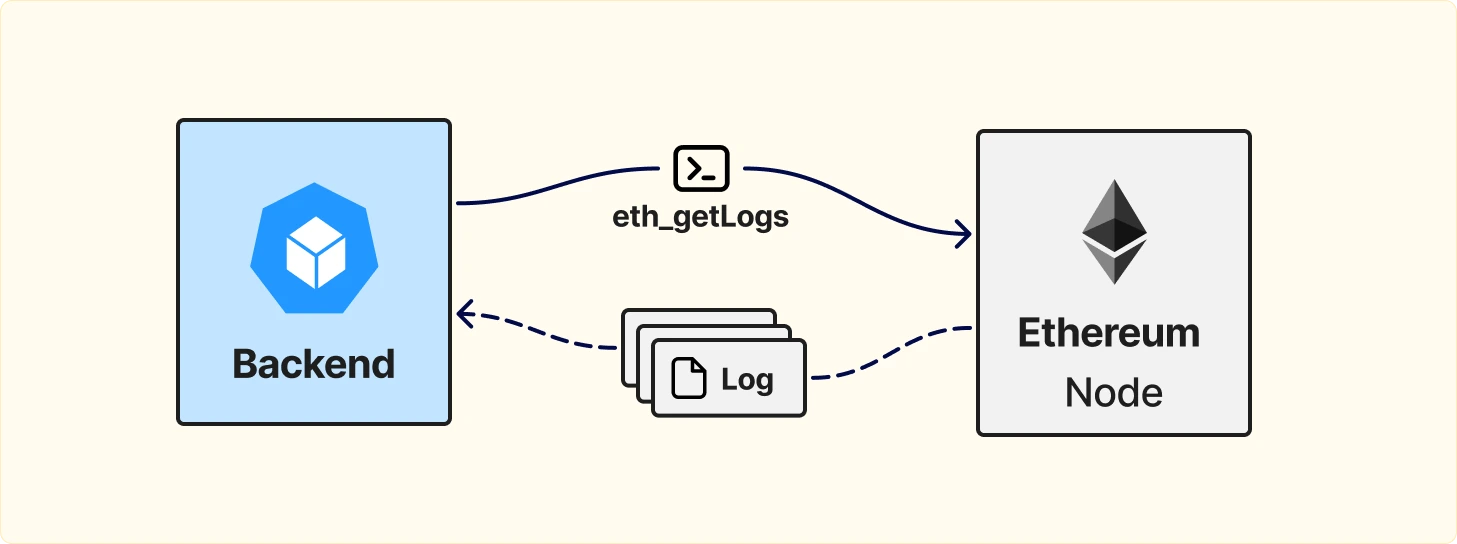
Ethereum-нода предоставляет JSON-RPC API, через которое внешний сервис может:
Logs — это специальная структура данных, которую разработчики смарт-контрактов специально закладывают в контракт с помощью событий (events).
Именно logs позволяют:
Для работы с ивентами Ethereum предоставляет метод eth_getLogs.
Это один из самых популярных и базовых инструментов для построения индексеров, потому что:
В рамках своей задачи eth_getLogs справляется хорошо и долгое время был стандартом де-факто для большинства простых индексеров.
Однако по мере роста требований к данным, объёму и скорости обработки становится очевидно, что одного eth_getLogs недостаточно.
Именно с этого момента и начинается эволюция индексеров, от простых RPC-сканеров к полноценным системам обработки блокчейн данных.
На раннем этапе eth_getLogs выглядит универсальным решением, но довольно быстро появляются сценарии, в которых его возможностей не хватает.
Ethereum логи содержат только ту информацию, которую разработчики контракта выносят во внешний мир.
Как следствие:
Если индексеру нужен, например, timestamp события, приходится:
На практике это быстро приводит к медленному и плохо масштабируемому пайплайну, где один RPC-запрос порождает десятки или сотни дополнительных.
Именно в этот момент архитектура индексера обычно эволюционирует к более «толстой» модели загрузки данных.
Ethereum ноды предоставляют более насыщенный по данным метод — eth_getBlockReceipts.
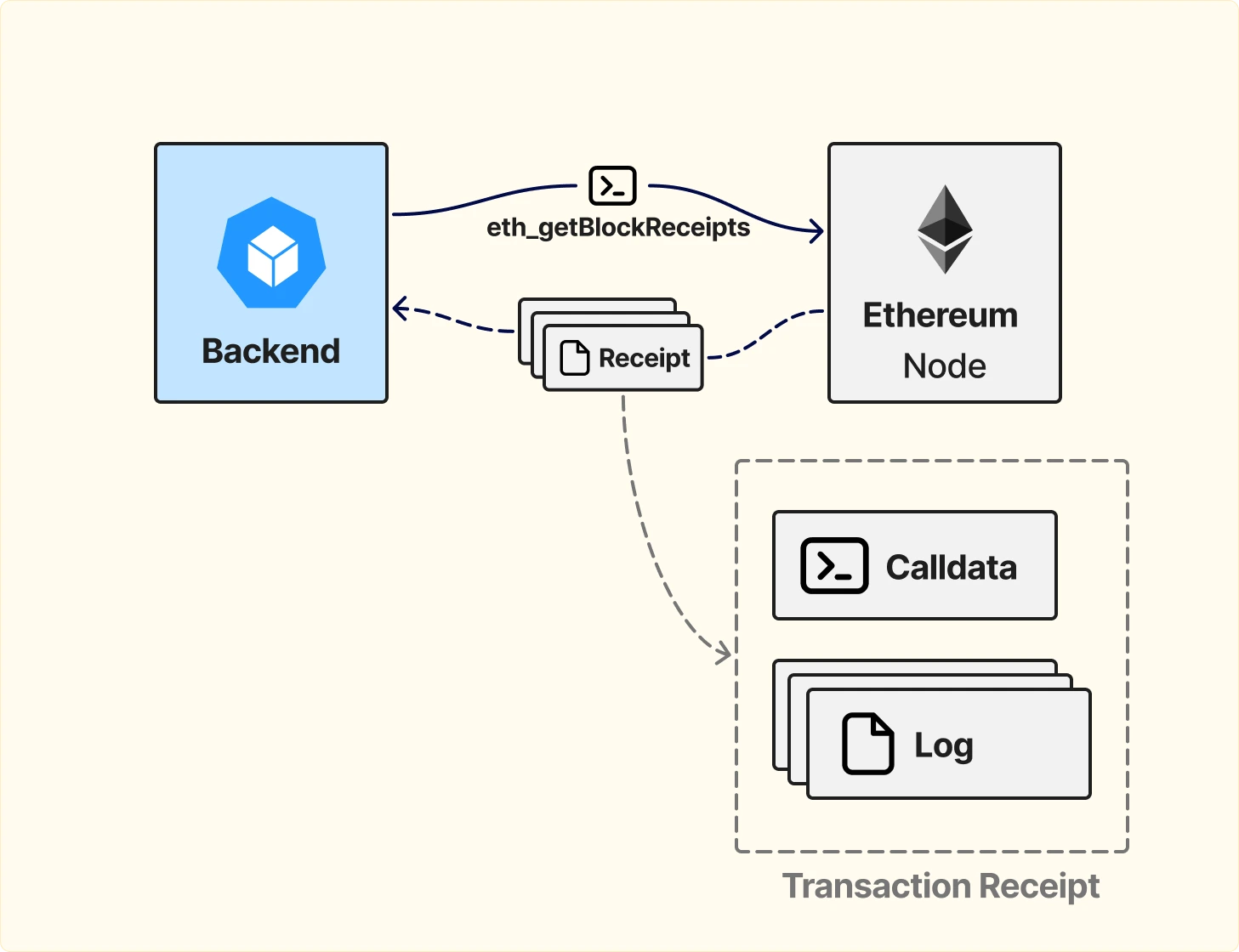
Этот метод возвращает подробную информацию обо всех транзакциях в конкретном блоке, включая:
Фактически, это почти полная картина всего, что произошло в рамках одного блока.
По сравнению с eth_getLogs такой подход:
Однако у этой модели есть и обратная сторона.
В отличие от eth_getLogs, eth_getBlockReceipts не поддерживает фильтрацию.
Нельзя сказать ноде:
В результате индексер вынужден:
Тем не менее, на практике этот подход всё равно часто оказывается лучше, чем каскадный RPC-пайплайн с догрузкой транзакций.
Но даже он не закрывает все потребности в кейсах
Хороший пример — отслеживание позиций в Uniswap V3.
Когда происходит swap:
Проблема в том, что:
Даже если индексер загружает весь блок целиком, этих данных там всё равно нет.
В результате для каждого свопа приходится:
Для Ethereum с блоками раз в ~15 секунд такой подход еще может работать:
Но в более быстрых сетях:
В этот момент становится понятно, что индексация на уровне RPC — это тупик для сложных продуктовых сценариев.
Решение этой проблемы существует даже в рамках стандартного Ethereum-деплоя. О нем поговорим дальше.
Ethereum-ноды предоставляют расширенный функционал через Debug API, однако его использование требует отдельной проверки.
Перед тем как делать индексер на основе debug-методов, важно учитывать:
Тем не менее, если Debug API доступен, он открывает принципиально новые возможности.
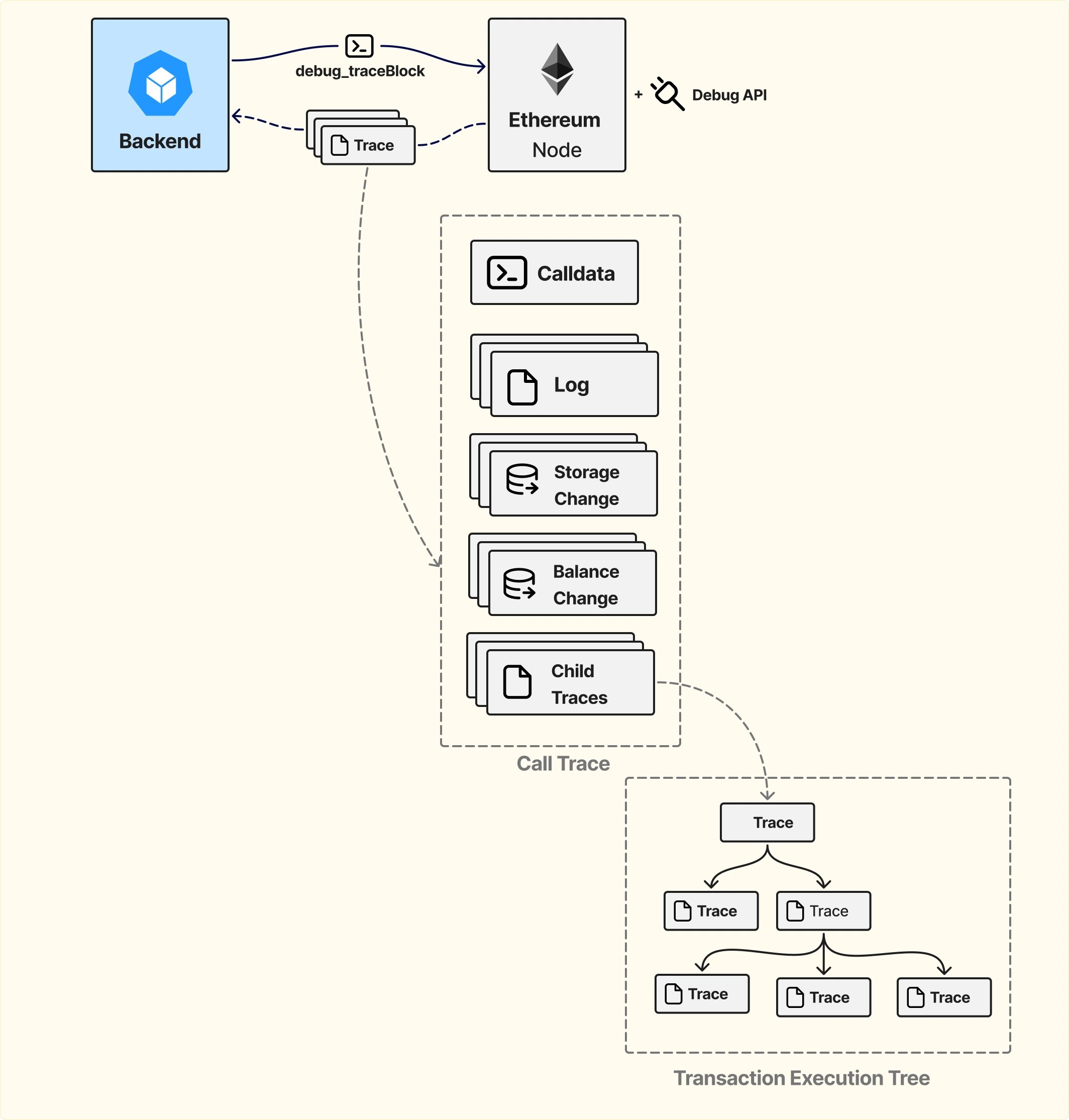
Ключевой метод — trace_block.
В отличие от стандартных RPC-вызовов, trace возвращает расширенную информацию об исполнении транзакций, включая:
Именно наличие state diffs делает trace критически важным для сложных кейсов.
Вернемся к примеру с Uniswap V3.
Для корректного пересчета комиссий по позициям необходимо знать:
С использованием trace:
Это устраняет необходимость делать отдельные eth_call или eth_getStorageAt для каждого события и сильно упрощает пайплайн.
Ещё одно важное отличие trace от стандартных receipts — наличие полного дерева вызовов.
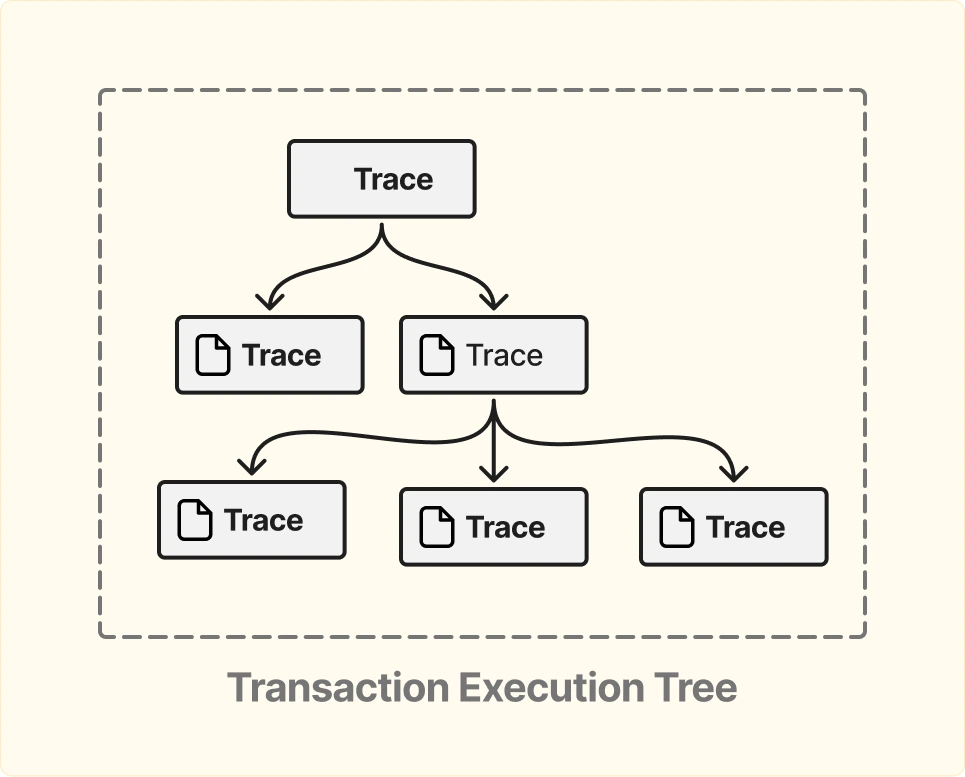
Например:
Trace позволяет видеть всю эту структуру как дерево, а не как плоский набор логов.
Это критично для:
Даже с использованием trace, мы все еще работаем в рамках pull-модели, напрямую общаясь с нодой. И здесь так же прослеживаются фундаментальные ограничения.
Идеальная модель для индексера – это подписка на поток данных, начиная с нужного блока или timestamp. Ethereum-ноды такого интерфейса не предоставляют. Да, существуют WebSocket endpoints, но у них есть жесткие ограничения:
Для систем, которые индексируют блокчейн целиком, отслеживают платежи или считают финансовые показатели потеря событий недопустима. В результате WebSocket-подписки используются редко, а основная логика всё равно строится вокруг поллинга ноды и повторных запросов.
Проблема 2. Chain reorganization (reorg)
В polling-модели нода не уведомляет клиента о форке, индексер просто запрашивает данные по номеру блока, факт реорга становится известен постфактум, если становится известен вообще.
Это оставляет два варианта:
От этих двух болей, которые мы описали выше появляется следующая реализация — продукт, который эти боли решает: FireHose от The Graph. Давайте разбираться, как устроен этот сервис.
Мы не можем просто поднять ноду, в этом нет смысла, потому что мы перенесем всю polling-модель о которой говорили ранее, и опять всё будет супер медленно. Поэтому нам нужно решать проблему со стримингом.

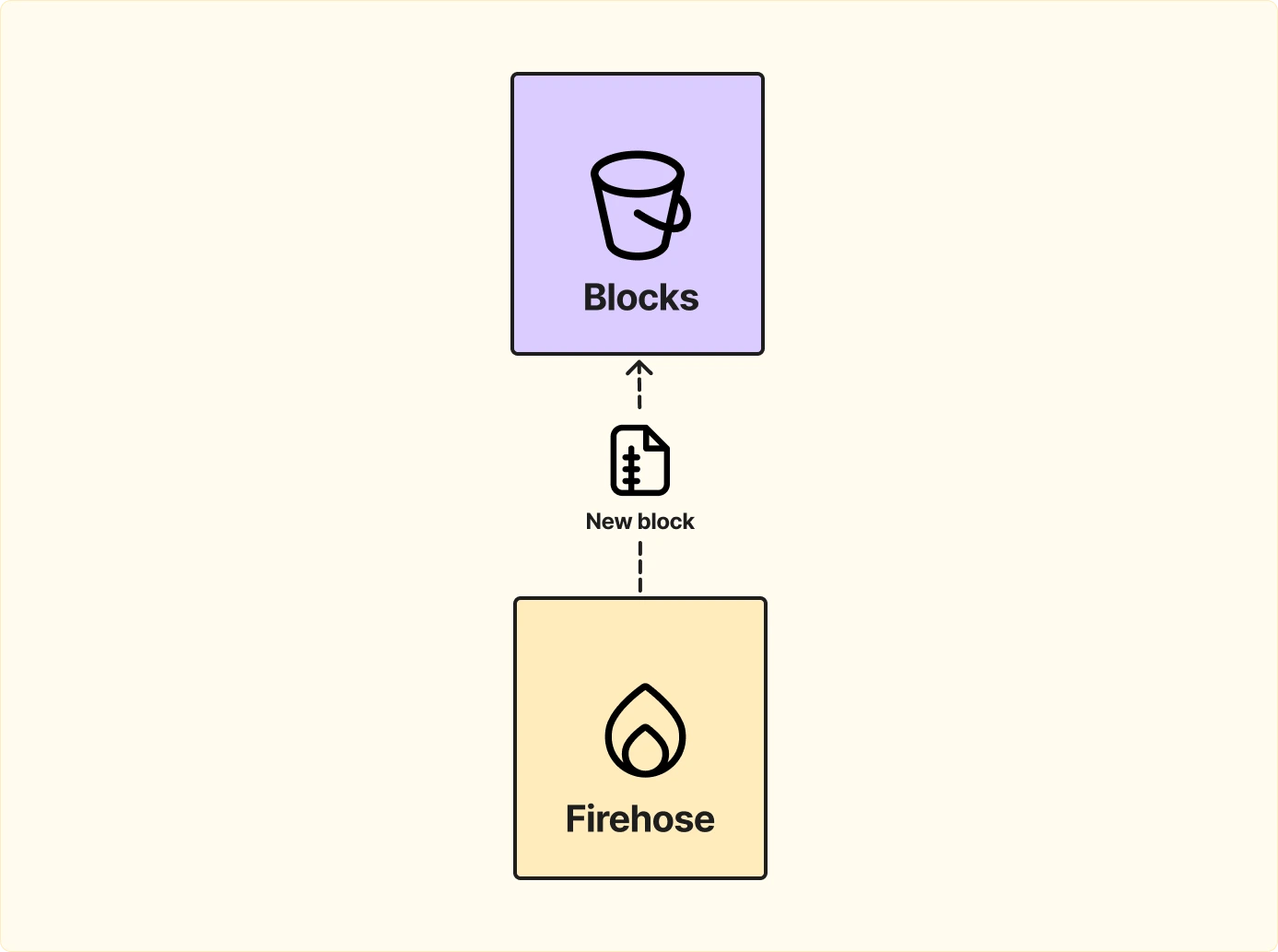
Идея такая: мы форкаем ноду и добавляем патч со стримингом, который будем читать своим сервисом. То есть, как только новый блок добавляется в ноду, мы сразу стримим его в pipe, из которого потом наш сервис его прочитает.
Обычная имплементация нод не рассчитана на исторический стриминг, то есть на возможность стримить данные с какого-то блока в прошлом.
Обычные ноды ориентированы на максимально эффективное хранилище и используют файловую систему. А это значит, что мы не можем бесконечно стримить нагрузку в storage.
Собственно, поэтому стандартная нода не поддерживает исторический стриминг.
Но мы делаем сервис, который умеет именно это — читать данные с любого момента в прошлом и стримить их клиентам без перегрузки ноды.
Мы будем использовать flat files, так как это минимальный юнит, который есть у ноды, и он максимально эффективен для хранения данных.
Во-вторых, S3 — это cloud-native решение. Это значит, что нам как разработчикам не нужно думать о менеджменте инфраструктуры и скейлинге:
Использование S3 позволяет построить масштабируемый и надежный слой хранения, который легко интегрируется с нашей системой стриминга.
Нода обычно работает по JSON-RPC — это стандартный HTTP, где данные стримятся как plain text. То есть в том виде, в котором пришли, они и передаются дальше.
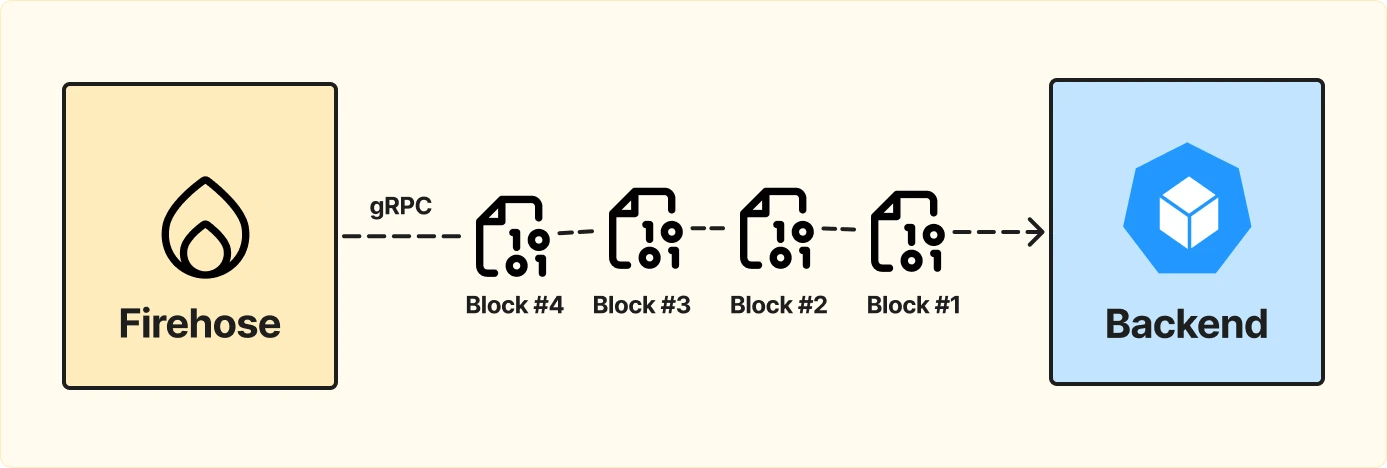
Мы можем взять что-то более эффективное, например gRPC.
Плюсы gRPC:
Итак, как будет проходить работа нашего сервиса Firehose:
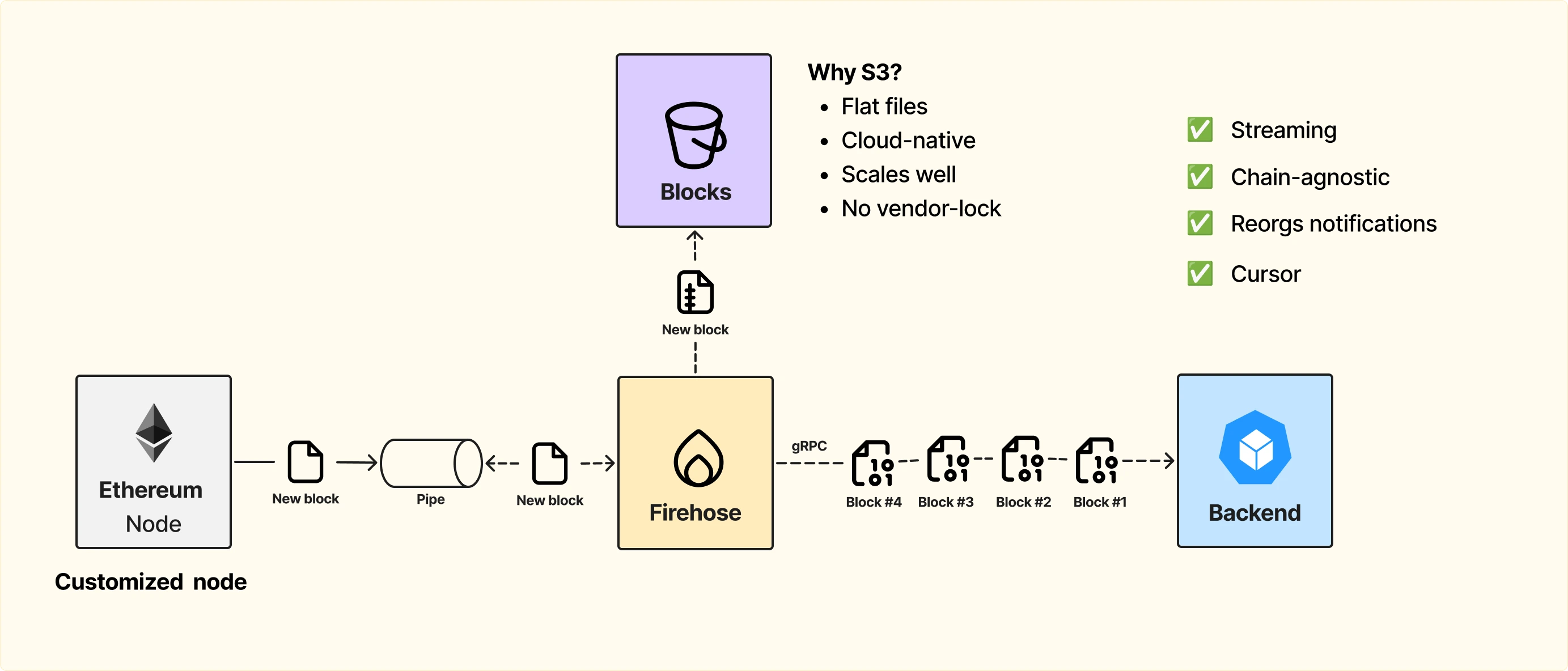
В этом интерфейсе важно реализовать Joined Block Source — механизм, который автоматически переключается между источниками блоков:
Если мы говорим о полной доступности данных, то здесь тоже есть над чем подумать. Схема работы Firehose в этом случае будет выглядеть немного сложнее.
Второй источник данных может работает по polling модели, медленнее, но позволит поддерживать непрерывность потока данных в случае проблем с основной нодой.
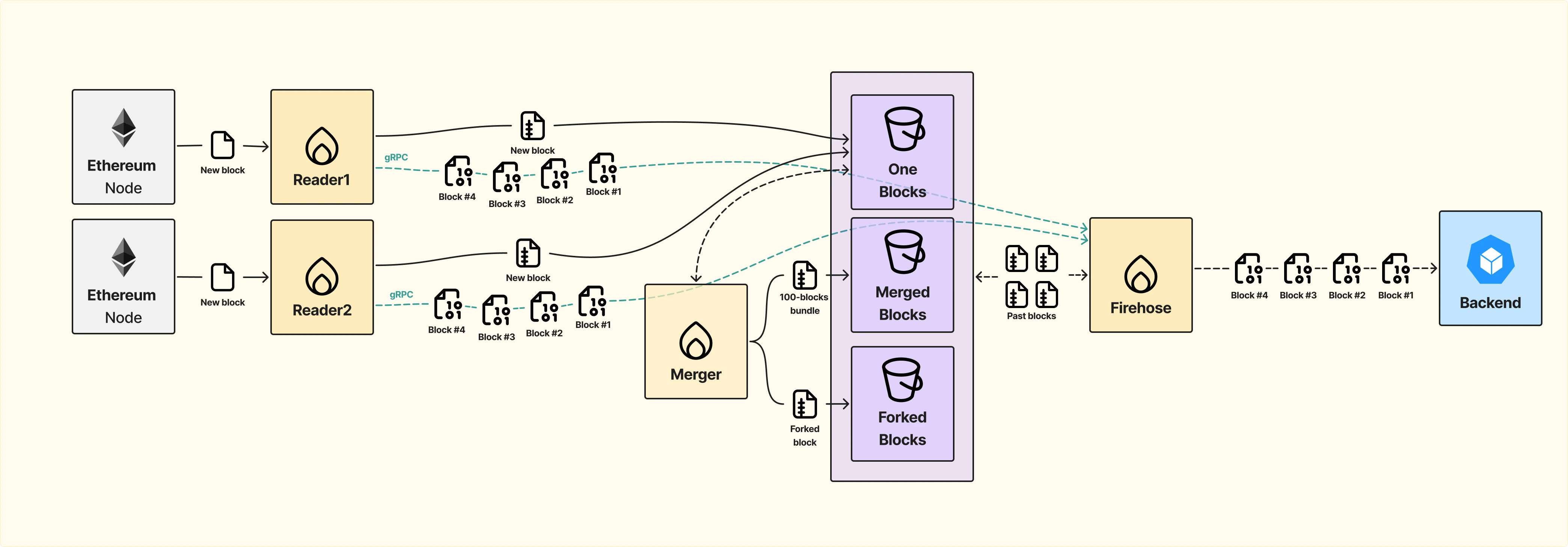
Чтобы оптимизировать работу с историческими данными и дедупликацию, в архитектуру Firehose добавляется отдельный сервис — Merger.
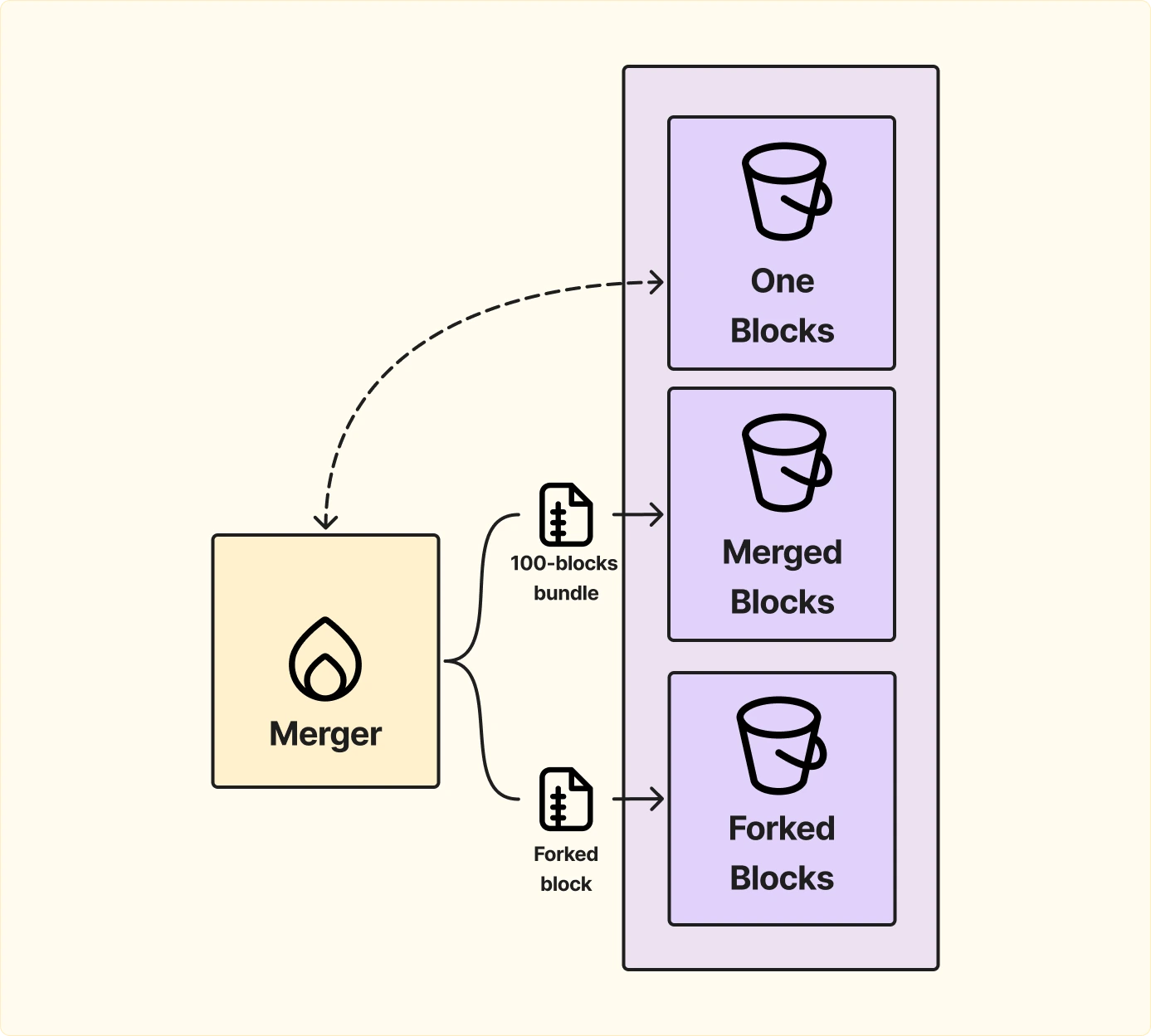
Теперь Firehose взаимодействует с тремя хранилищами:
Если пользователь запрашивает большой диапазон исторических данных, блоки уже не будут выдаваться поштучно, а пакетами по 100 штук, это ускорит обработку и уменьшит нагрузку на систему.
Даже в Firehose остаётся одна проблема — Избыточный стрим данных
Самый эффективный подход — позволить разработчикам писать свои фильтры и получать только те данные, которые нужны для конкретного приложения.
Substreams — это движок, который выполняет пользовательский код на сервере для каждого блока. Код пишется как функция, которая на вход принимает блок, а на выход — отфильтрованные данные. Функция компилируется в WebAssembly.
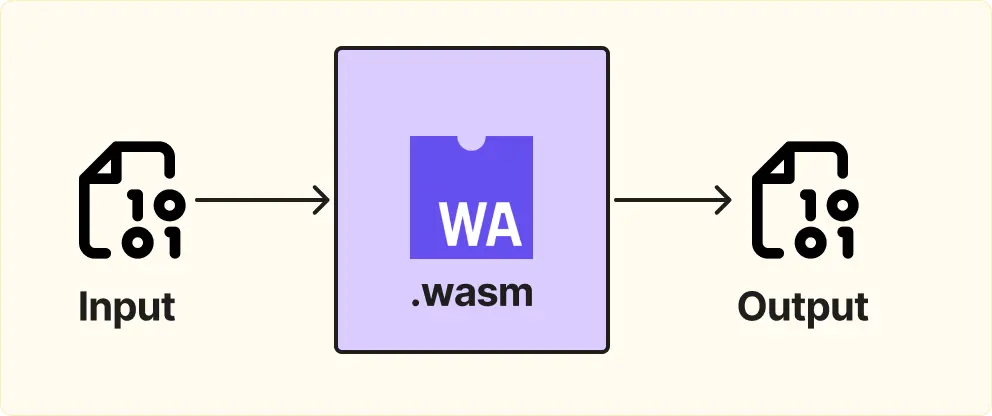
Пример работы:
С появлением Substreams архитектура Firehose стала более гибкой. Substreams добавляется как отдельный сервис, аналогичный Firehose, и позволяет разработчикам определять какие данные они хотят получать.
Пользователи загружают функции, которые выполняются для каждого блока. Эти функции могут фильтровать данные по конкретным контрактам, событиям или любым другим критериям. В результате разработчики получают только то, что им нужно, вместо полного потока блокчейн-данных за всё время.
Давайте посмотрим как изменился наш workflow.
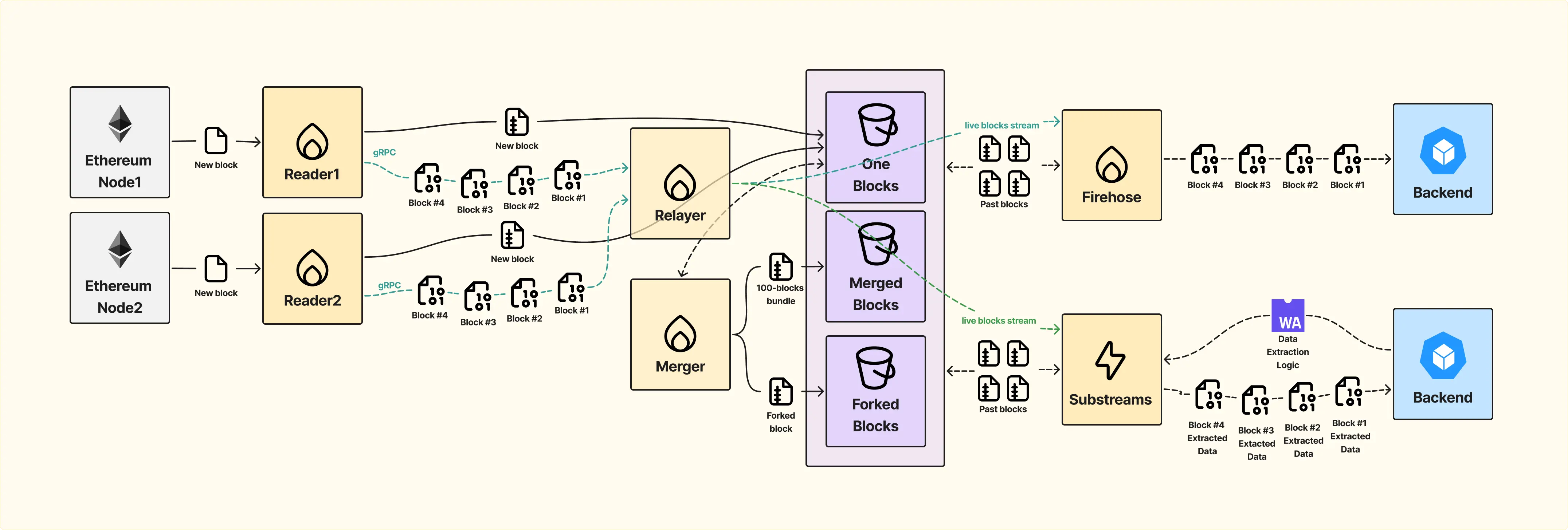
Появление Substreams сделало необходимым вынести логику дедупликации из Firehose в отдельный сервис — Relayer. Ранее Firehose был единственным потребителем данных и сам занимался удалением дубликатов.
С новой схемой Relayer объединяет данные от Firehose и Substreams, обеспечивая:
Теперь давайте разберём, как Substreams масштабируется.
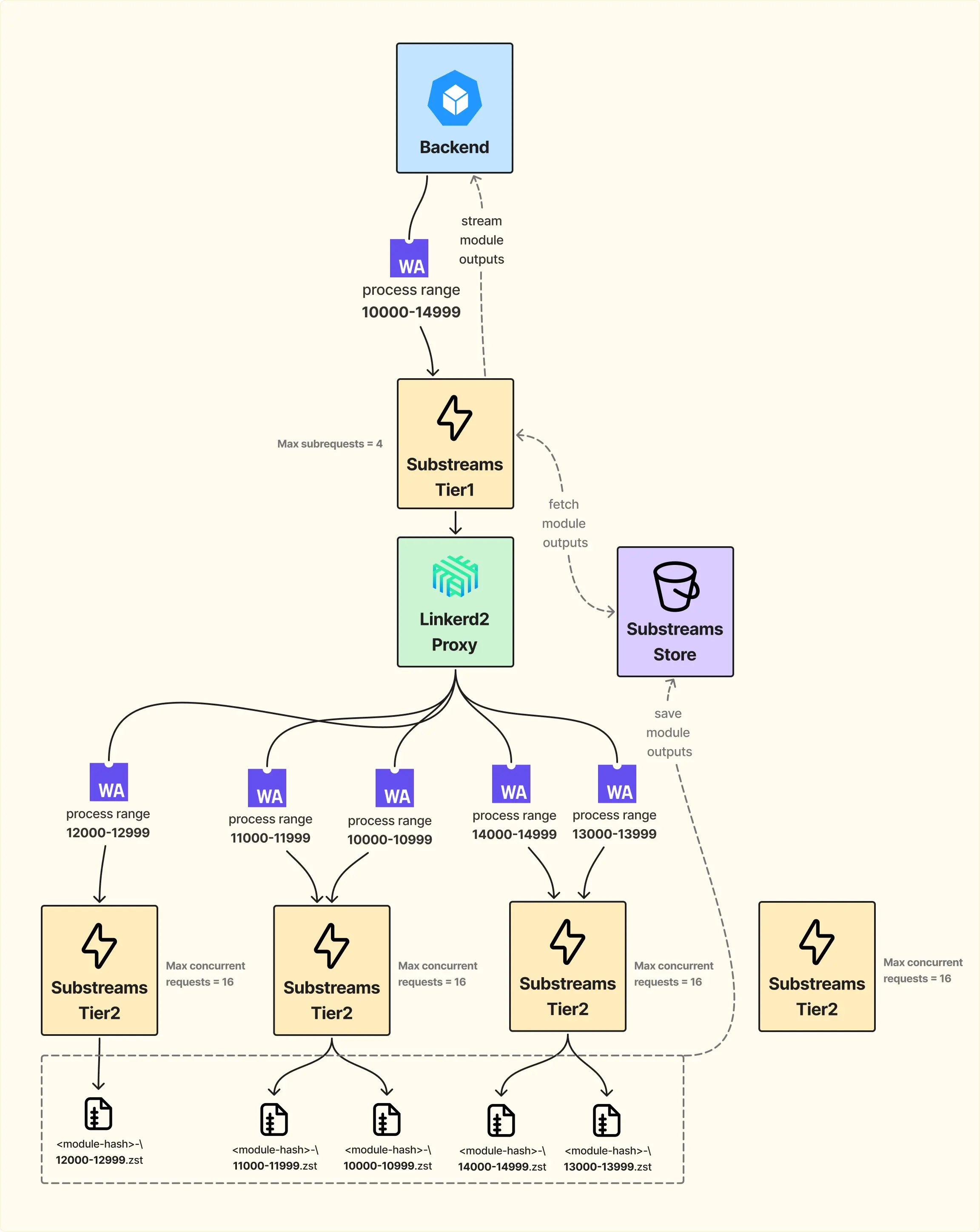
Сервис разделён на два уровня: Front Tier и Worker Tier.
Когда пользователь отправляет запрос на обработку диапазона блоков, например с 10000 по 14999 (5000 блоков), Front Tier принимает этот запрос и распределяет задачи между воркерами.
Каждый воркер может одновременно обрабатывать несколько ренжей (до 16). Через прокси запросы распределяются между воркерами пакетами по примерно 1000 блоков. Как только воркер заканчивает работу, он складывает данные в отдельный bucket с кешем. Об этом bucket мы поговорим позже, когда будем рассматривать пакетирование данных.
То есть мы собираем данные в bucket, а обратно в Front Tier стримим не сами данные, а прогресс. Это нужно, чтобы понимать, когда ренж завершён и можно начать стримить данные дальше, или чтобы знать, если где-то в функции пользователя произошёл revert, потому что не факт, что пользователь написал функцию правильно.
Front Tier ждёт, пока обработается первый ренж из запрошенных, стримит его обратно пользователю, затем проверяет следующий. Если ренж готов — отправляет его, если нет — ждёт завершения обработки. Так процесс идёт до последнего ренжа, сохраняя порядок блоков.
Теперь давайте поговорим, как устроены функции, которые можно загружать в Substreams, и как их можно оптимизировать с помощью кеша.
Самое простое, что приходит на ум, — использовать кеш. Рассмотрим пример:
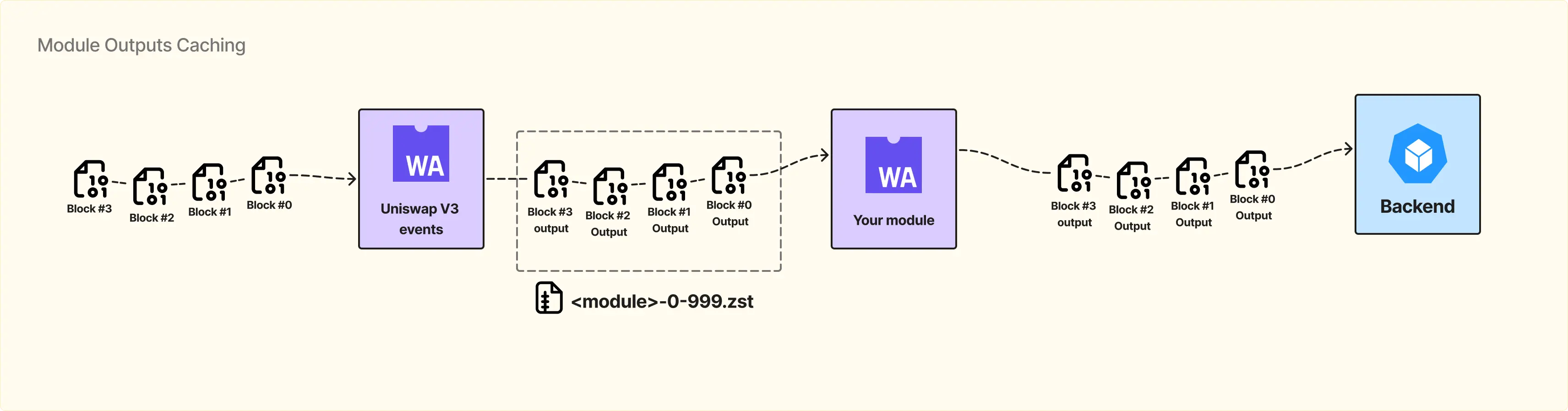
Есть модуль, который кто-то уже написал до нас. Он принимает на вход блоки из Merged Blocks Bucket и извлекает из них все события Uniswap V3 в рамках одного блока. Модуль ничего с этими данными не делает, просто отбирает нужные события. На выходе мы получаем меньше информации, чем было в исходном блоке — только события Uniswap V3.
Далее наш сервис сохраняет эти данные в Substreams Store Bucket.
Теперь в нашей функции можно указать, что входные данные — это не сами блоки, а output этого модуля (Uniswap V3 events), и подключить к запросу соответствующий модуль. Сервер понимает, что данные уже доступны в кеше, и не тратит ресурсы на повторную обработку блока. Он просто берёт отфильтрованные данные из Substreams Store.
Если учесть биллинг, где пользователь платит за объем данных, которые он получает, такой подход упрощает работу разработчика и снижает стоимость обработки, так как можно использовать уже подготовленные данные из кеша вместо повторного вычисления.
Следующий уровень оптимизации — Index-модули.
Отличие Index-модулей от обычных модулей в том, что у них стандартизированный формат вывода. На выходе для каждого блока формируется массив ключей, с помощью которых можно быстро понять, есть ли интересующая информация в блоке.
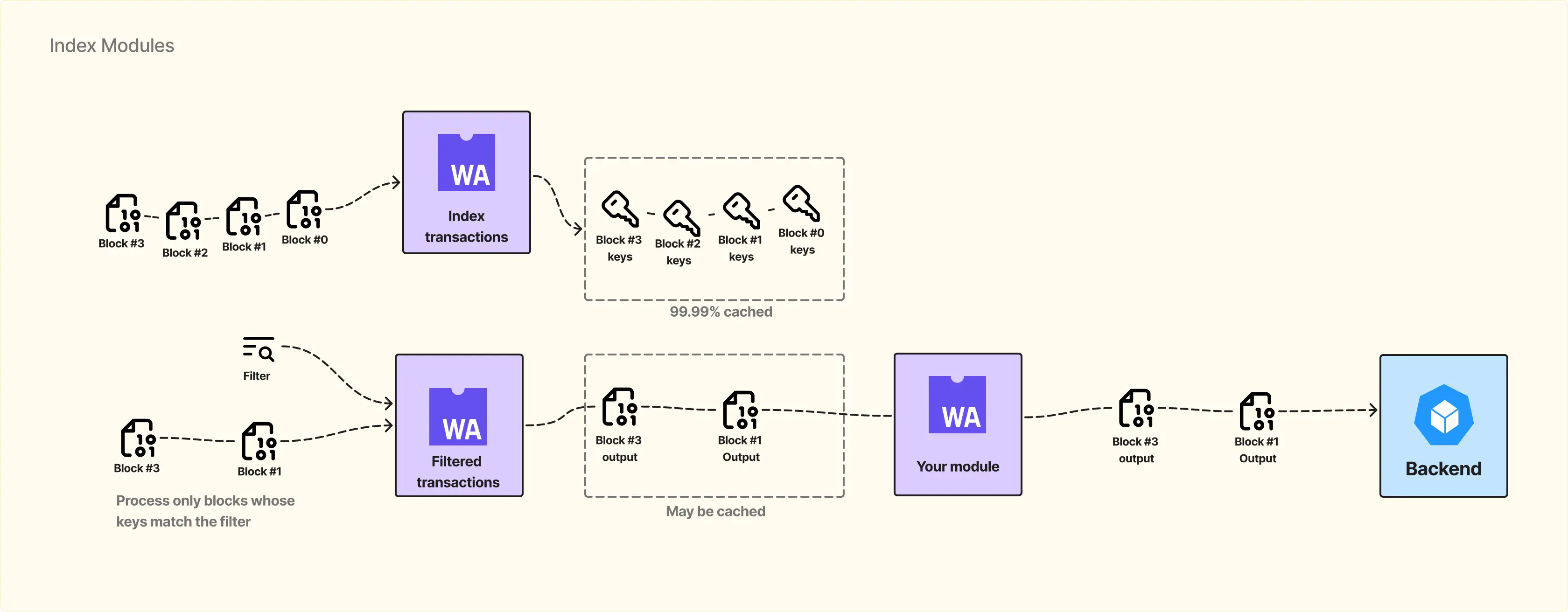
Например, индекс-модуль принимает на вход raw blocks и создаёт для каждого блока индекс с такими данными, как:
Далее можно написать модуль, например Filtered Transactions, который использует этот индекс. В манифесте указываем, что модуль использует индекс и передаем его бинарный файл. Также нужно описать фильтр, по которому работает индекс. Например, мы хотим получить только транзакции по Radiym.
Сервер достаёт индексы из кеша и определяет, в каких блоках есть транзакции с Radiym. На вход модуля Filtered Transactions попадают только эти блоки, что значительно экономит ресурсы.
Интересный момент: если кто-то уже обрабатывал эти блоки и создавал фильтр по Radiym, то, скорее всего, данные уже есть в кешe Substreams. В этом случае пользователь может пропустить этап прогона по индексу и сразу получить результат из Filtered Transactions module, который уже содержит отфильтрованные данные.
На этом этапе нужна система, которая всё, что мы собрали, корректно уложит в базу данных.
Для этого используется SQL Sink, разработанный The Graph, исходный код доступен в открытом доступе и который можно поднять у себя. Сервис подключается к Substreams server и потребляет данные.
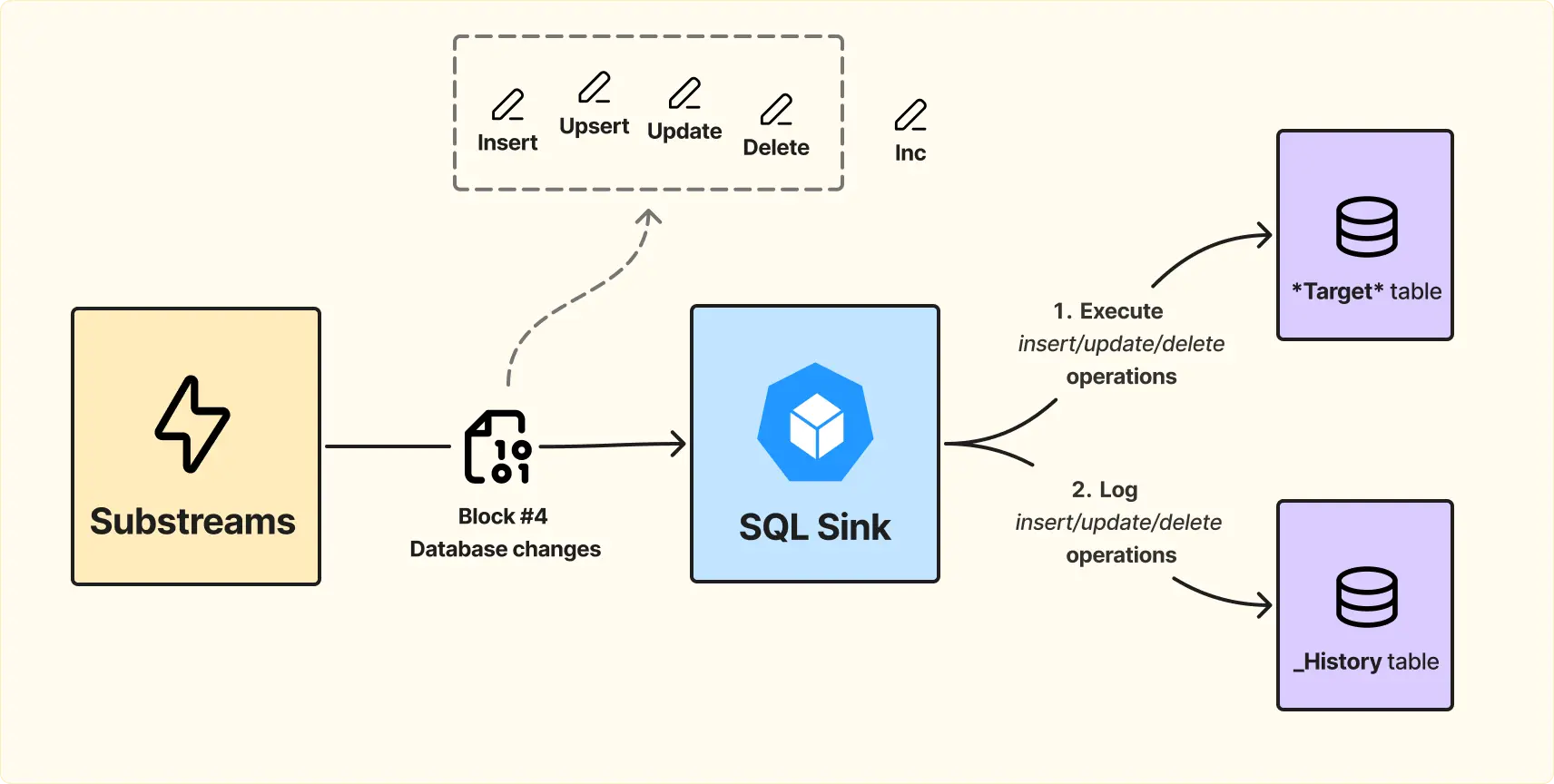
SQL Sink ожидает, что модули Substreams будут отправлять данные в определённом формате, чтобы можно было однозначно определить, как их разместить в базе данных. Формат описывает, что делать с блокчейн-данными: insert, upsert, update или delete по конкретным primary keys с соответствующими данными.
При этом остаётся параллельная обработка данных на уровне Substreams module. На выходе получаем массив инструкций, который сообщает, какие операции нужно выполнить в базе. Пользователю остается реализовать только модули, которые реализуют этот формат.
Дальше происходит следующее:
Это необходимо для того, чтобы в случае chain реорга и получения сигнала о последнем валидном блоке, система могла корректно откатить изменения и синхронизироваться с новой цепочкой.
На схеме ниже показан кейс того, как это будет обрабатываться.
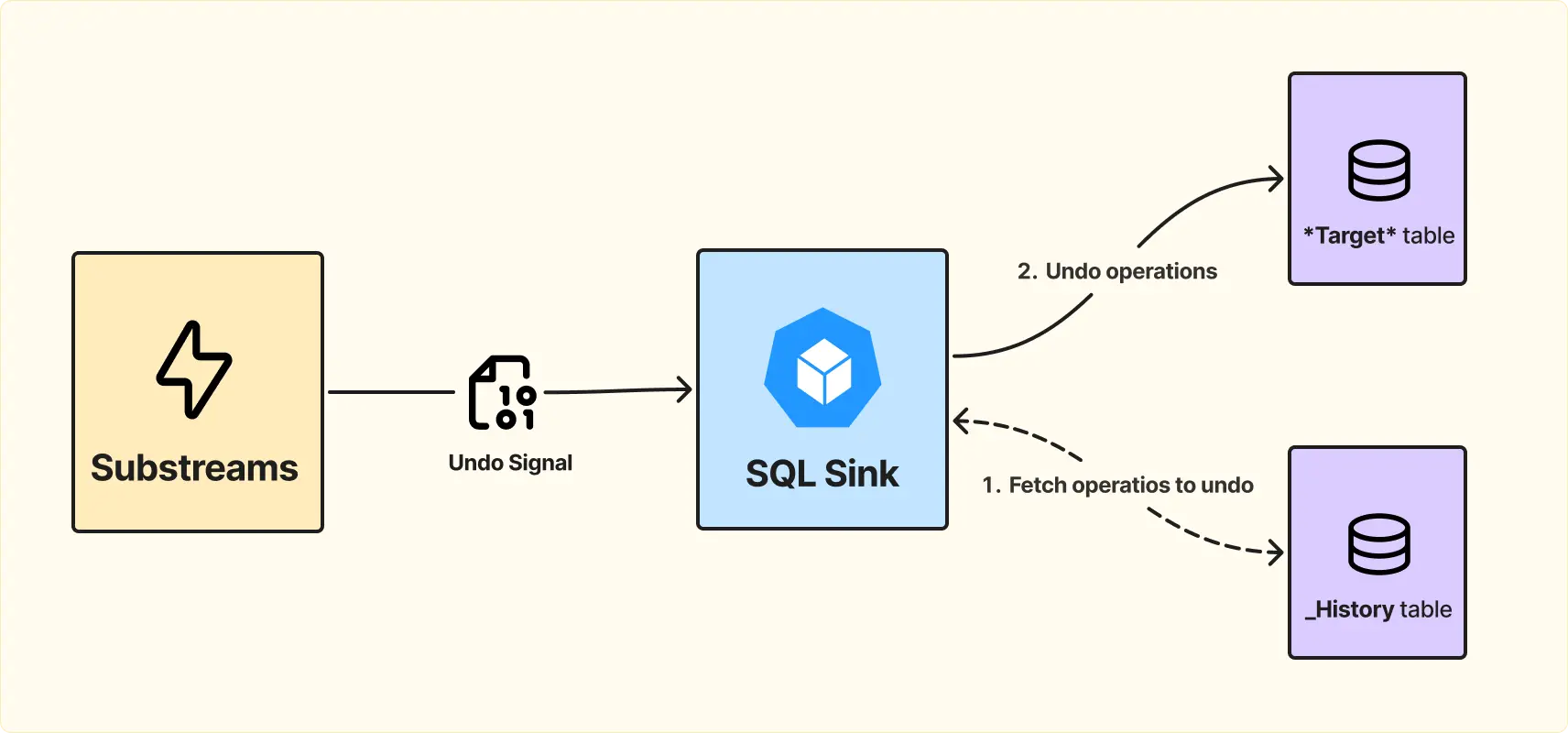
В случае реорга сервис обращается к History table, получает все операции в диапазоне «невалидных» блоков и откатывает их.
Суть в том, что реализация SQL Sink достаточно гибкая. Текущая версия ограничена базовыми операциями (insert, upsert, update, delete), но при необходимости её можно форкнуть и добавить новые операции. Например, в решении для Blum возникла необходимость добавить операции типа increment, которые не укладывались в стандартный набор операций. Подробнее об этом можно почитать в нашем кейс-стади.
Итак, что можно сделать: форкнуть SQL Sink, написать модули, которые помимо базовых операций возвращают дополнительные, такие как increment, и реализовать handler, который трансформирует новую операцию в SQL-запрос.
Ещё один уровень гибкости: не обязательно использовать SQL Sink. Пользователь может написать свой sink и сам решать, как обрабатывать и куда укладывать данные. Сервис предоставляет стримы и параллельную обработку данных, а дальше пользователь выбирает: SQL — есть готовый SQL Sink, нужна нестандартная операция — форкаем и расширяем SQL Sink, нужен другой тип хранения — можно написать sink с нуля.
Наконец, давайте разберём, как всё это укладывается в сравнении с Subgraph.
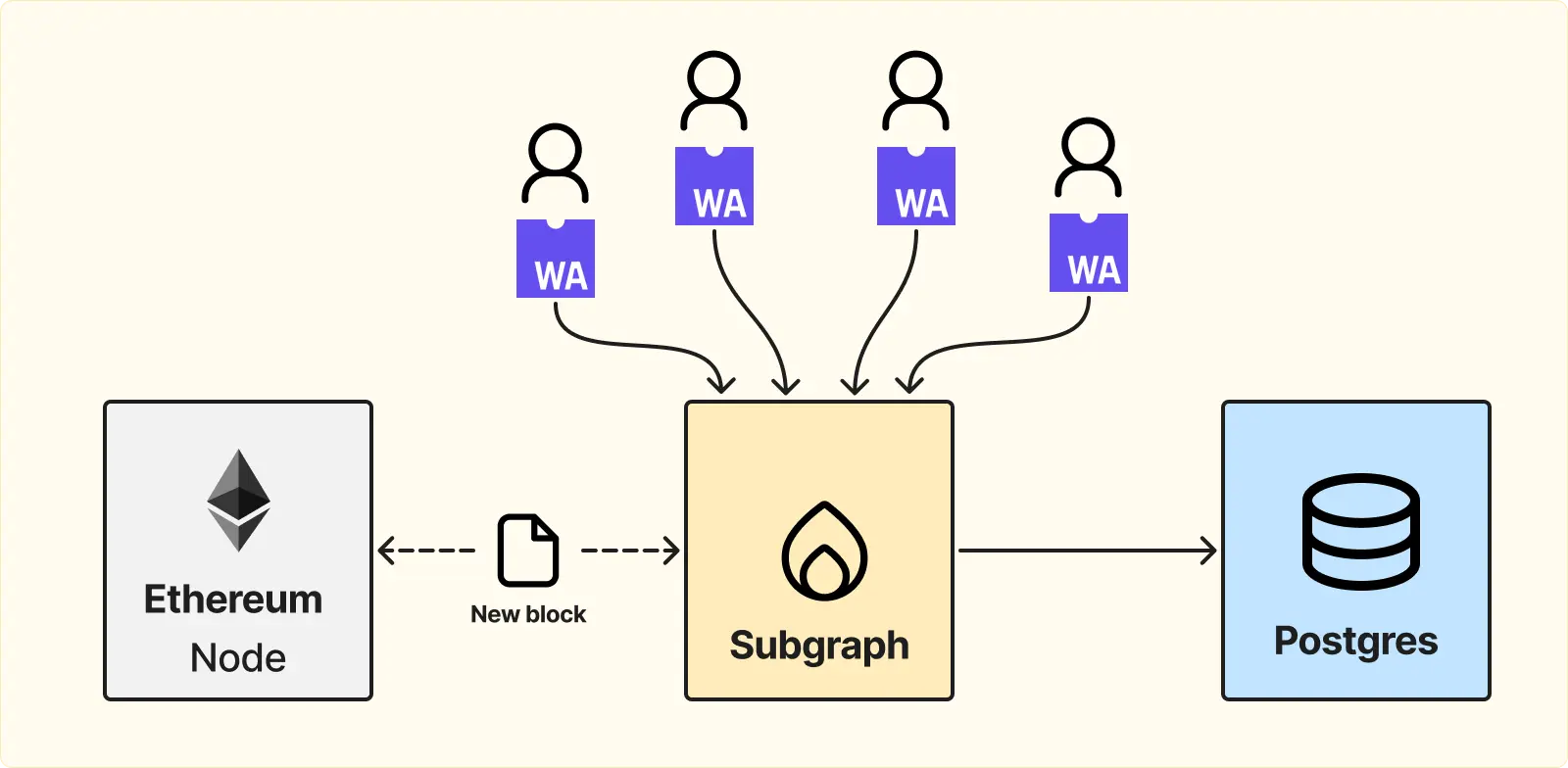
Subgraph — это готовая «коробка», в которую пользователи один раз загружают свой код, скомпилированный в WebAssembly. В этом коде пользователь описывает все сценарии работы: как реагировать на событие, как обрабатывать транзакцию и так далее.
При этом Subgraph не имеет собственного хранилища с блоками. Каждый раз, когда нужно обработать какой-то диапазон блоков, Subgraph обращается к ноде.
Плюсы такого подхода:
Минусы:
Мы прошли путь от классического поллинга нод до реализации Firehose с Substreams и SQL Sink. Такой подход позволяет:
Использование Firehose и Substreams даёт системное решение проблем, с которыми сталкиваются классические индексеры, и делает работу с данными надёжной и предсказуемой, даже для быстрых сетей вроде Solana.
Rock’n’Block — это студия разработки Web3-продуктов, создающая production-grade инфраструктуру блокчейн-сервисов и децентрализованные приложения. Мы помогаем командам быстрее запускать высокопроизводительные продукты, строить UX для миллионов пользователей и выделяться на конкурентных рынках.
Наша команда имеет почти десятилетний опыт блокчейн разработки, поддерживая продукты для более чем 71 млн пользователей DeFi, с суммарной капитализацией систем $2,5 млрд.
Следите за нами в X, чтобы не пропустить новые глубокие обзоры по блокчейн-разработке. Подписаться








%201.webp)



