
Blockchain Data Streams — Aave Events Indexer on Aptos

Solution Overview
We delivered an Aave scalable blockchain indexer on Aptos that streams only relevant transactions from any chain version, parses events and resource updates in parallel, and exposes datasets via GraphQL. The system gives a practical path to indexing blockchain data.
Objectives
- Fast bootstrap from an arbitrary Aptos version.
- Flexible queries via GraphQL for BI, dashboards, and product features.
- Coverage of Aave’s data: Supply/Withdraw events, ReserveData, A/V token total supply, user balances.
Approach
There are three data sources on Aptos: Node REST API, Indexer API (GraphQL), and Transaction Stream Service.
We chose TSS + Indexer SDK (Rust) as this blockchain indexing service allows:
- streaming from any version;
- server-side filters;
- and a clean framework to compose processors.
Scope & data model
- Events → time-series tables: supplies, withdrawals.
- Resources → 1:1 mapping: reserves, token_supplies, token_balances.
The Process
Analytics & source selection
We compared:
- Node REST API — useful, but polling makes indexing blockchain slow and costly.
- Indexer API (GraphQL) — provides more structured data and more flexible filtering than the Node API, but still relies on polling.
- Transaction Stream Service — streams transactions from any version, supports flexible filters with logical operators, and comes with the Indexer SDK, which simplifies both connecting to the service and building the remaining indexing components.
Compared with many blockchain indexing tools or any alternative blockchain indexer, TSS avoided polling and reduced client CPU while preserving correctness.
Pipeline
Demystifying Indexer SDK
The Indexer SDK is a Rust framework for building indexers on Aptos, powered by the Transaction Stream Service.
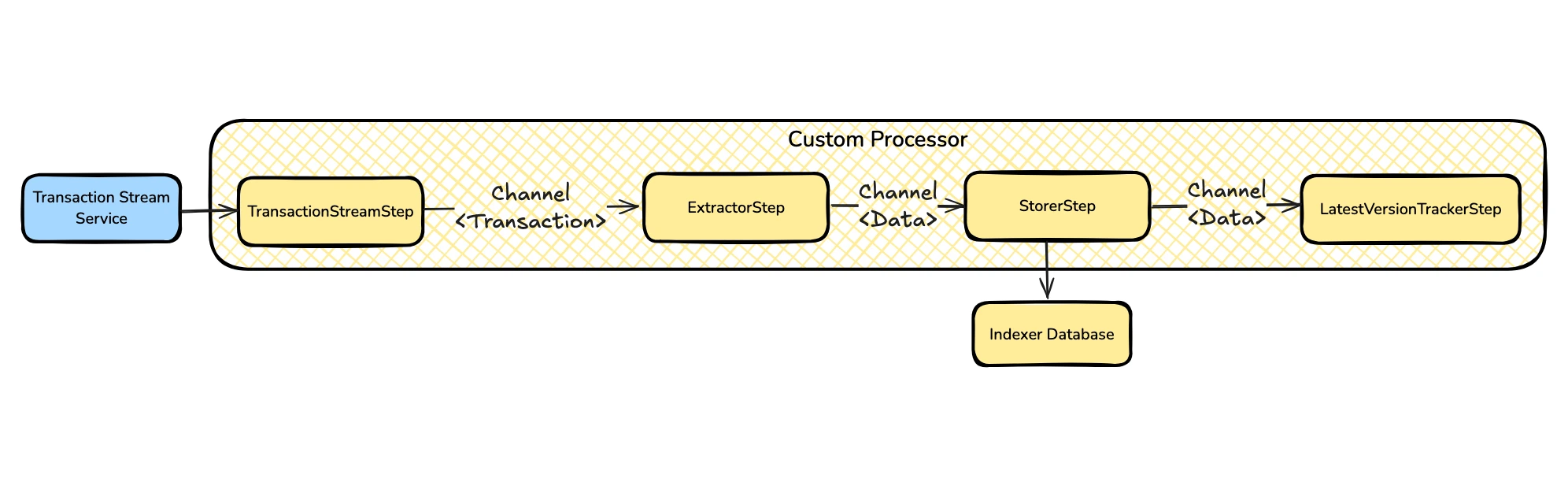
The Indexer SDK allows you to implement an indexing flow as a directed graph of independent steps. Let’s dive into each step in detail.
Transaction Stream
This step is provided by the Indexer SDK, serving as the starting point for all processors. During this step, a connection to the Transaction Stream Service is established, initiating data streaming.
To minimize client-side processing, server-side filters are configured to stream only transactions whose state changes involve the Aave Pool.
Extractor
At this step, the relevant data is extracted from the transactions. Since the processor logic is written in pure Rust, we can process transactions in parallel, taking advantage of libraries like rayon.
Parsing events
Similar to Ethereum, every transaction contains a list of events that describe what happened during its execution. To find Supply and Withdraw events, we simply filter them by their type string:
0x...::supply_logic::Supplyfor Supply events0x...::supply_logic::Withdrawfor Withdraw events
The type string consists of three parts:
0x...– the Aave Pool address; the account that owns the pool modulepool– the module name; a module is like a smart contract, defining structs, functions, and constantsSupply/Withdraw– the event name
Parsing state changes
One of the key challenges for a blockchain indexing development company is obtaining the actual state changes from transactions. In Aptos, unlike most blockchains, each transaction includes the updated state of every resource modified during execution. This is highly advantageous for indexers, as it allows direct access to the new state without re-engineering on-chain math, which is often required on Ethereum.
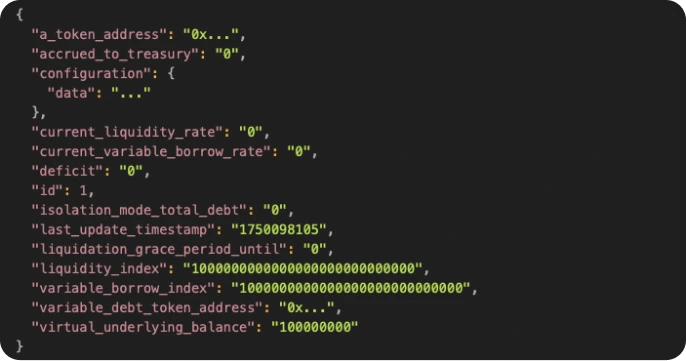
To find reserve updates, we filter transaction changes that update:
0x...::pool::ReserveData– which represents the on-chain state of a reserve (e.g., USDC, APT)
Example (truncated for readability):
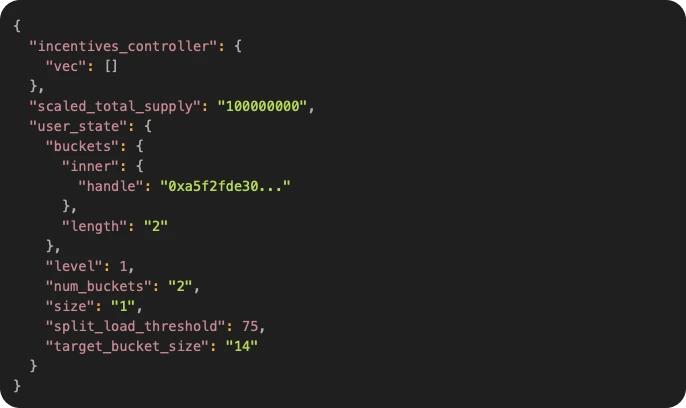
For A/V token data, we parse:
0x...::token_base::TokenBaseState– containing total supply and user balances.
Example (truncated for readability):
The user_state stores user balances in a Smart Table – Aptos scalable hash table implementation based on linear hashing. Data in the smart table in divided into buckets, so only the relevant buckets updates are present in transactions. To capture these updates, we filter table write changes that match the handle from user_state.
Example (truncated for readability):

The decoded value contains the set of user balances within 0x0000000000000000 bucket.
Storer
At this step, the data extracted in the previous stage is committed to the database.
For events, committing approach is straightforward, since events are simply time-series data that we store as is:
- Supply events → supplies table
- Withdraw events → withdraws table
For resources, since they are independent and can be updated in parallel on-chain, we mirror this design in the database by creating a 1:1 mapping between resource and database table:
- Reserve ****data updates → reserves table
- A/V token supply updates → token_supplies table
- A/V token user balance updates → token_balances table
This design, combined with the fact that transaction data contains complete resource data (including unchanged fields), enables us to commit all resource updates using upsert operations only.
Because the upserts rely on complete data rather than incremental calculations (e.g., adding or subtracting balances), we can avoid wrapping them in database transactions. This allows us to safely split updates into chunks and execute them in parallel, significantly improving indexing speed.
The Indexer SDK provides helpers for chunking and executing queries in parallel, allowing developers to focus on writing queries rather than managing execution details.
Latest Version Tracker
Once processing is complete, the indexer saves a cursor in the database. This ensures that subsequent runs continue from the correct transaction without data duplication.
This step is provided out of the box by the Indexer SDK.
Enabling GraphQL API
Since the Indexer SDK does not include an API layer, we use Hasura over Postgres to expose the indexed data via GraphQL.
The Results
- Scalable indexing. The solution delivers fast bootstrap and flexible queries via GraphQL, aligned with the stated goals.
- Complete data coverage. The indexer captures Supply and Withdraw events, Reserves data, A/V tokens total supply, and A/V token user balances.
- Efficient streaming architecture. Using Transaction Stream Service, the system streams transactions from any version with server-side filters targeting the Aave Pool, reducing client-side processing and simplifying the remaining components through the Indexer SDK.
- Parallel extraction. Processor logic in Rust (with rayon) enables parallel transaction handling, including event parsing by type strings and state parsing of ReserveData and TokenBaseState, plus Smart Table bucket updates via handle.
- Robust storage model. Events are written to time-series tables (supplies, withdraws), while resources map 1:1 to snapshot tables (reserves, token_supplies, token_balances). Upsert-only writes, split into chunks and executed in parallel, improve blockchain indexing speed without wrapping operations in database transactions.
- Reliable continuity. The Latest Version Tracker persists a cursor so subsequent runs resume from the correct transaction without duplication.
Immediate access layer.Hasura over Postgres exposes the indexed datasets via GraphQL, enabling the intended flexibility for downstream queries.





%201.webp)



